当大多数人还在用“帧率”“光追”“显存带宽”来衡量一张显卡时,NVIDIA 已悄然跨过传统图形的边界——2026年初发布的 GeForce RTX 5090,不再仅仅是一块游戏显卡,而是一台专为 神经渲染(Neural Rendering) 而生的 AI 图形处理器。它的对手,早已不是上一代 RTX 4090,而是 NVIDIA 自家的数据中心旗舰 H100。
什么是神经渲染?为什么它如此重要?
传统图形渲染依赖多边形建模、光栅化、光线追踪等物理模拟手段,计算成本高、效率低。而 神经渲染 则另辟蹊径:让 AI 模型直接“生成”图像、光照、材质甚至动态场景。
- 像素不再“算出来”,而是“推理出来”;
- 游戏世界不再由美术资源堆砌,而是由神经网络实时“想象”;
- 最极端情况下,100% 的画面像素可由 AI 生成(NVIDIA 官方数据)。
这不仅是画质的跃升,更是整个图形流水线的范式革命。
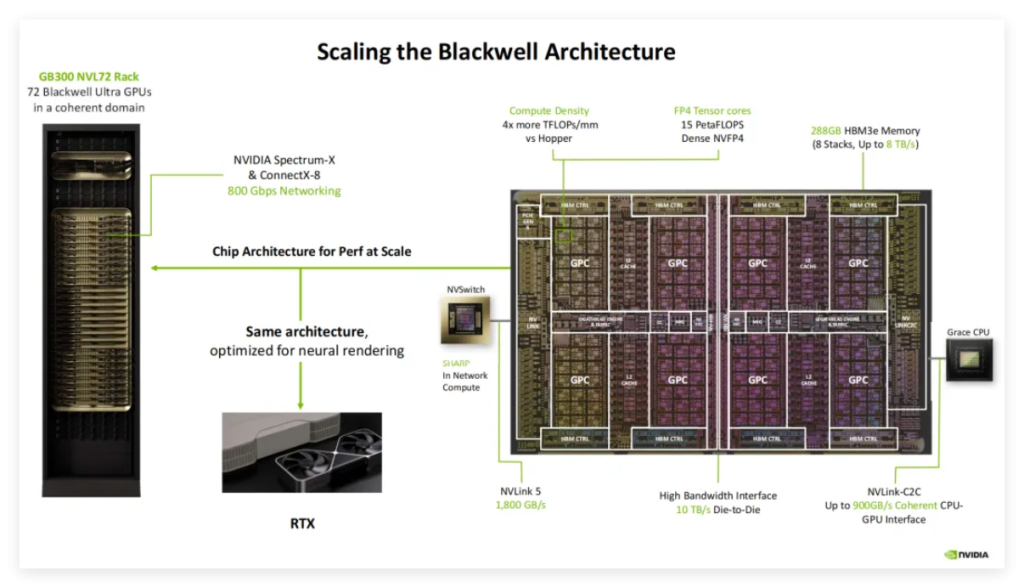
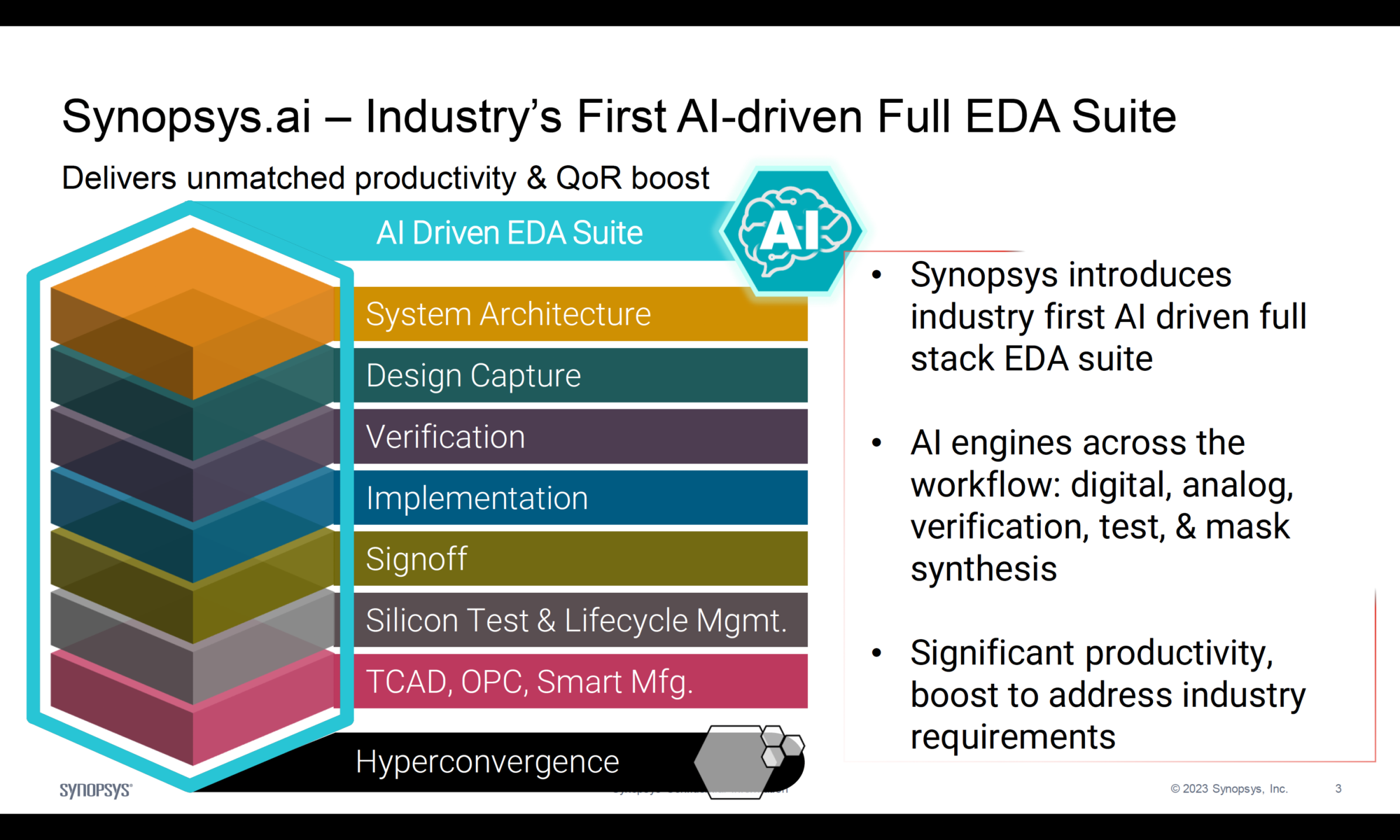
RTX 5090 核心技术:Blackwell 架构下的 AI 原生设计
RTX 5090 首次将数据中心级 Blackwell 架构 下放至消费端,其关键技术远超传统 GPU:
表格
| 技术 | 说明 | 意义 |
|---|---|---|
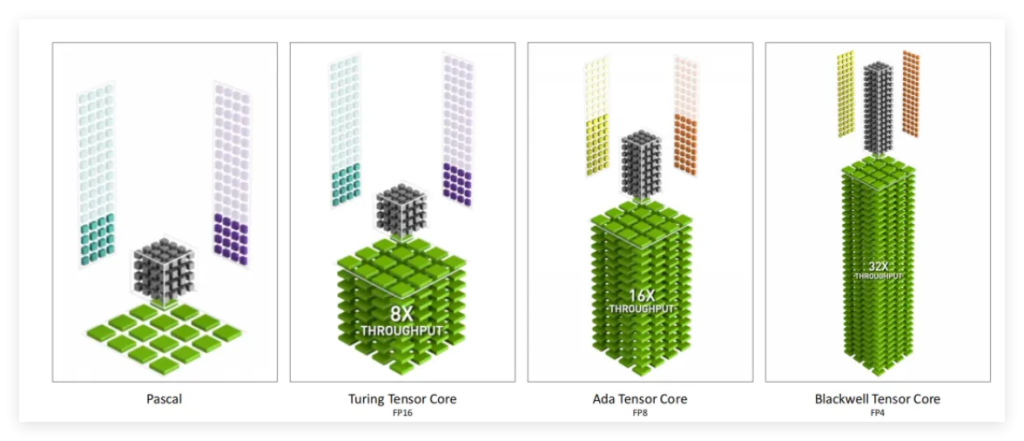
| FP4 Tensor Core | 支持 FP4 精度张量运算,吞吐量比 H100 的 FP8 提升 32 倍 | 大幅降低 AI 推理能耗,使本地运行复杂神经渲染模型成为可能 |
| 神经着色器(Neural Shader) | 每个着色单元集成微型 AI 模型,可动态生成纹理、光照、几何细节 | 取代传统着色流程,实现“内容即推理” |
| AI 管理处理器(AMP) | 独立协处理器,负责调度多个 AI 模型(如 DLSS、NPC 行为、场景生成)并行运行 | 确保图形与 AI 任务无冲突,维持高帧率与低延迟 |
| MIG 多实例技术(消费端首搭) | 一张卡可分割为多个独立 AI+图形实例 | 支持同时运行游戏、直播推流、AI 创作等多任务 |
💡 关键洞察:RTX 5090 不是“能跑 AI 的显卡”,而是 为 AI 渲染而从头设计的芯片。
对比 H100:同源架构,不同使命
虽然 RTX 5090 与 H100 同属 Blackwell 家族,但定位截然不同:
表格
| 维度 | RTX 5090(消费端) | H100(数据中心) |
|---|---|---|
| 核心目标 | 实时神经渲染、游戏、创作者 AI | 大模型训练、科学计算、企业 AI 推理 |
| FP4 支持 | 全面启用,优化图形推理 | 主要用于 LLM 训练压缩 |
| 显存 | 32GB GDDR7(带宽 >1.5TB/s) | 80–96GB HBM3e(带宽 3.35TB/s) |
| 功耗 | ~600W(支持 ATX 3.1 电源) | 700W(需专用服务器供电) |
| 软件栈 | Game Ready 驱动 + DLSS 4 + Neural FX SDK | CUDA + cuDNN + Triton Inference Server |
共同点:两者共享 Blackwell 的底层 AI 加速能力,意味着 开发者可在 RTX 5090 上预研神经渲染算法,无缝部署至 H100 集群。
核心应用场景:谁需要 RTX 5090?
1. 下一代游戏与元宇宙
- NPC 由小型 LLM 驱动,具备真实对话与行为逻辑;
- 场景动态生成,无需预加载资源包;
- DLSS 4 实现“AI 超分 + 帧生成 + 光照重建”三位一体。
2. AI 内容创作(AIGC)
- 实时生成 4K 视频、3D 模型、材质贴图;
- Stable Diffusion + NeRF 联合推理,秒级输出逼真场景;
- Adobe、Blender 插件直接调用 Neural Shader。
3. 科研与仿真
- 物理仿真中用神经网络替代部分 PDE 求解;
- 医学影像重建、气候模型可视化加速;
- 本地运行轻量化数字孪生系统。
4. 边缘 AI 推理节点
- 凭借 MIG 技术,一台工作站可同时服务多个 AI 应用;
- 替代部分入门级服务器,在影视棚、设计工作室部署私有 AI 渲染集群。
结语:图形的未来,是“想”出来的
NVIDIA 并未止步于“更快的光追”或“更高的帧数”。通过 RTX 5090,它正在推动一场静默的革命:将图形从“计算模拟”转向“AI 生成”。
正如首席架构师 Marc Blackstein 所言:
“我们不是在更新显卡,而是在更新‘渲染’的定义。”
在这个新范式下,H100 是云端的大脑,而 RTX 5090 就是每个创作者、玩家、工程师桌面上的 神经渲染终端。
图形行业的 AI 化,已不可逆转。而你,是否准备好进入这个“被 AI 想象出来”的世界?