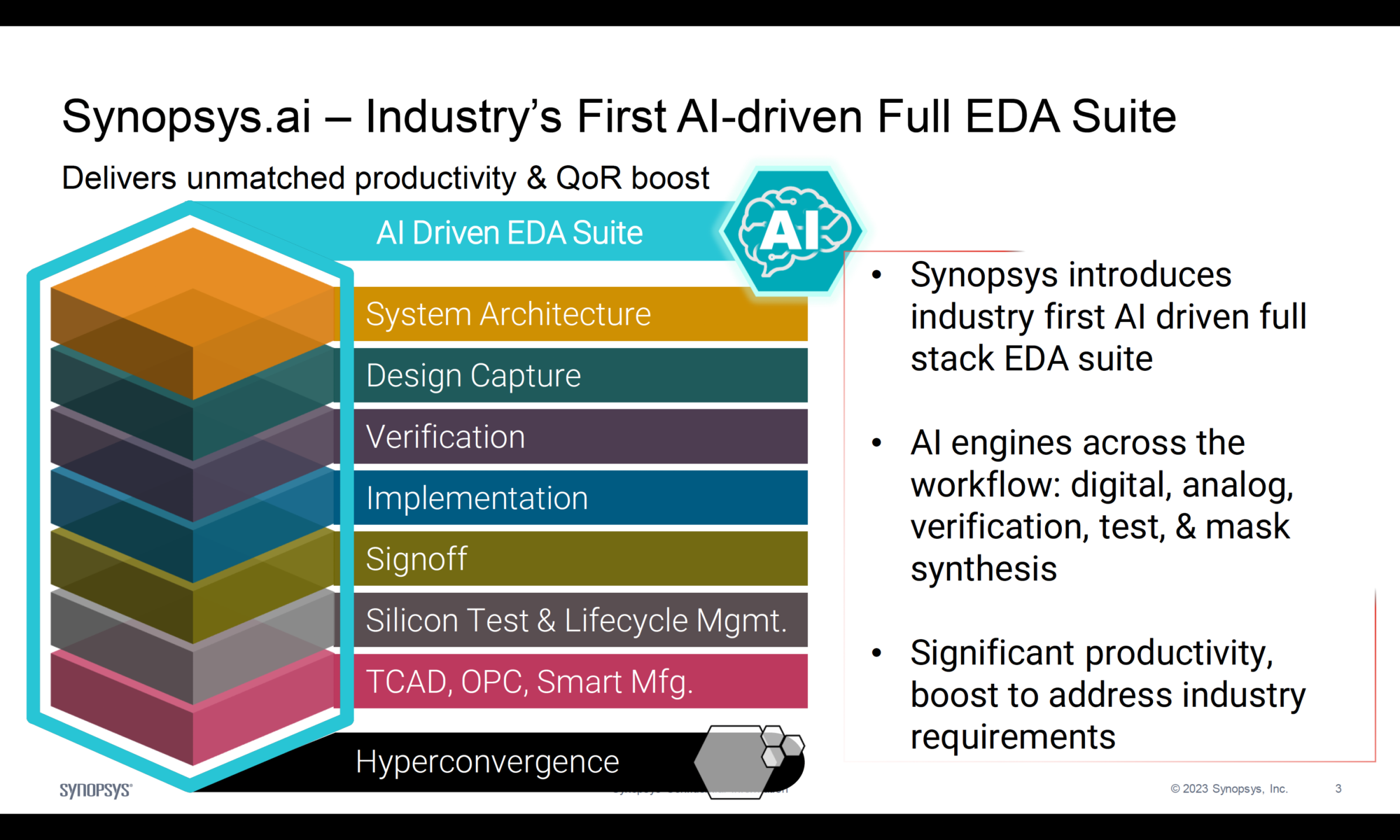
2026年1月,在英伟达GTC大会的聚光灯下,当黄仁勋正式宣布下一代AI平台以“Rubin”命名时,整个计算世界再次屏息。Rubin的问世,不仅宣告了Blackwell时代的巅峰,更提前两年绘制了通往2026年、支持万亿参数AI模型的计算蓝图。这不仅仅是一次产品迭代,而是英伟达为驾驭指数级增长的AI复杂度,对整个硬件生态系统进行的一次革命性重构。
性能飞跃:专为下一代AI推理而生
Rubin平台的核心目标是突破当前AI训练的瓶颈,将重心转向海量模型的高效推理与持续学习。
- 颠覆性的推理性能:官方宣称,Rubin平台的推理算力将达到Blackwell架构的5倍以上。这意味着,一个在Blackwell上需要数秒生成回答的千亿参数大模型,在Rubin上可能仅需瞬间。这对于实时AI应用,如自动驾驶决策、交互式AI助手和金融高频交易分析,是颠覆性的体验升级。
- 能效比再创新高:通过全新的芯片工艺(预计采用台积电N3或更先进制程)、架构优化及先进的封装技术,Rubin在提供巨幅算力提升的同时,致力于将单位性能的功耗大幅降低,为超大规模数据中心解决日益严峻的能耗与散热挑战。
- 内存带宽与容量革命:为承载万亿参数模型,Rubin预计将引入更高速的HBM4或更高规格的存储解决方案,内存带宽有望突破10TB/s,模型参数可以更完整地驻留在高速内存中,从根本上减少与慢速存储的数据交换,极大提升推理和持续训练的吞吐量。
平台化架构:超越单一GPU的系统级重构
Rubin的划时代意义,在于它首次清晰展示了英伟达从“GPU供应商”向“全栈式计算平台构建者”的彻底转型。它不再仅仅是一颗GPU,而是一个由多类芯片深度耦合的超级计算单元。
1. 核心芯片:Vera CPU + Rubin GPU
- Rubin GPU:采用全新的核心微架构,预计将大幅增加SM(流式多处理器)数量与效率,并针对矩阵运算(尤其是FP8、INT8等低精度推理计算)和新型AI算法(如MoE专家混合模型)进行硬件级优化。
- Vera CPU:这是Rubin平台的另一大亮点。英伟达将推出首款基于Arm Neoverse架构的自研数据中心CPU“Vera”,与Rubin GPU通过新一代NVLink-C2C技术实现超紧密耦合。CPU与GPU不再是分立协作,而是共享统一内存空间的“超级芯片”,极大降低了数据搬运延迟,为复杂AI工作流(如检索增强生成RAG)提供无缝算力支持。
2. 互联与网络:NVLink 6.0 + X1600网络交换机
- 第五代NVLink:Rubin芯片间的互连带宽将提升至上一代的数倍,允许数千颗GPU如同一颗巨型GPU般协同工作,为单一万亿参数模型提供无瓶颈的算力供给。
- X1600 Spectrum交换机:配合更新的网络架构,将提供前所未有的800Gb/s甚至更高的端到端带宽,并增强网络计算能力,使数据中心规模的Rubin集群能以极高的效率运行。
3. 系统集成:从板卡到机柜的全新设计
- Rubin平台将催生新一代的HGX/RGX服务器参考设计。这些系统会为CPU+GPU的紧密集成、超高速互联布线和极高的功率密度进行专门优化,成为未来AI工厂的标准“建筑模块”。
前瞻性技术参数(基于早期路线图与行业预测)
以下是Rubin平台关键组件的预期技术规格汇总:
| 组件类别 | 产品名称 | 预期关键规格 |
|---|---|---|
| GPU | Rubin GPU | • 采用台积电N3或更先进制程 • 集成HBM4高带宽内存,带宽 >10TB/s • 支持下一代低精度格式(如FP6) • 第五代NVLink-on-Chip互连 |
| CPU | Vera CPU | • 基于Arm Neoverse V系列核心 • 与Rubin GPU通过NVLink-C2C实现缓存一致性 • 专为AI负载优化的多核架构 |
| 互联 | NVLink 6.0 | • 芯片间互连带宽大幅提升(预计达1.8TB/s以上) • 支持更复杂的拓扑结构 |
| 网络 | X1600交换机 | • 端口速率800Gb/s或更高 • 集成更强大的In-Network Computing功能 |
重塑未来:Rubin平台的革命性应用场景
Rubin平台所解锁的算力与系统效率,将直接催化一系列此前受限于技术瓶颈的颠覆性应用:
- 万亿参数通用人工智能(AGI)的基石:Rubin是第一个明确以万亿参数模型的实时推理和持续训练为目标设计的平台。它将使研发机构能够构建和部署具备更强逻辑、更广知识和更低延迟的AGI原型,是通向强人工智能的关键基础设施。
- 科学发现的“数字孪生”引擎:在气候模拟、药物发现、核聚变研究等领域,Rubin能够运行前所未有的高分辨率、多物理场耦合的实时模拟,在数字世界中近乎“预演”现实,极大加速科学突破。
- 实时自动驾驶城市网络:Rubin提供的超低延迟推理能力,使得“车-路-云”一体化成为可能。每辆车不再仅是独立个体,而是城市级实时感知与决策网络的一个节点,协同优化交通流量,彻底避免事故。
- 永不休眠的AI工厂与物理AI:在智能制造和机器人领域,Rubin平台能驱动全天候运行的、具备自主学习和优化能力的“AI工厂”。同时,它能支持更复杂的具身智能(物理AI),让机器人能实时理解并灵活应对混乱的真实物理世界。
- 沉浸式元宇宙与全息通信:Rubin能实时生成和渲染超逼真的3D世界,并支持大规模用户同时低延迟接入。结合AI,它能实现真正的全息通信,让远程互动与面对面无异。
结语:通往下一个计算纪元的船票
英伟达Rubin平台的发布,本质上是在为未来两年后爆发的AI需求提前铺设铁轨。当行业还在消化Blackwell的震撼时,Rubin已经描绘了一个由CPU与GPU深度融合、算力网络化、内存统一化所构成的下一代计算范式。
它不仅是性能参数的简单叠加,更是对“如何构建一台面向AI时代的超级计算机”这一命题的体系化回答。对于任何志在参与下一轮AI浪潮竞赛的国家、企业和研究者而言,理解和布局Rubin平台所代表的技术方向,无异于拿到了通往下一个计算纪元的早期船票。AI的未来,正在以芯片为砖石,被重新建造。